
 420614836
420614836

开启NLP新时代的BERT模型,是怎么一步步封神的?
日期:2018-12-13 | 访问量:7623
来源:搜狐科技
NLP领域的伸手党们,上个月简直像在过年!
不仅号称谷歌最强NLP模型的BERT如约开源了,而且最新版本还支持中文,可以用于中文命名实体识别的Tensorflow代码!最关键的是,这个强大的模型还横扫11项记录,"阅读理解超过人类"。
谷歌团队的Thang Luong更直接宣告:BERT模型开启了NLP的新时代。“BERT在手,天下我有”的既视感啊!
人工智能漫长的发展史上,能够让行业“锣鼓喧天,鞭炮齐鸣”的算法模型还真不多见。不过,在跟风成为这个模型的舔狗之前,我们先来扒下它的外衣,看看到底有没有那么神奇。

什么是BERT模型?
这个让全球开发者们为之欢欣鼓舞的新模型,全称是Bidirectional Encoder Representation from Transformers,即对Transformer的双向编码进行调整后的算法。
这种预训练模型所针对的核心问题,就是NLP的效率难题。
众所周知,智能语音交互要理解上下文、实现通顺的交流、准确识别对象的语气等等,往往需要一个准确的NLP模型来进行预测。
但越是精准的模型,越是依赖于海量的训练语料,往往需要人工来进行标注和制作,因此,通过某种模型来预训练一个语言模型,帮助进行超大规模的表征学习,就成了一种靠谱且被广泛采用的方法。
而传统采用的预训练模型,比如AI2的 ELMo,以及OpenAI的fine-tune transformer,也同样需要通过人力标注来制作训练数据。
譬如说常用的中文汉字有3500个,词汇数量50万,制作中文语言预训练模型的参数数量自然也就十分庞大,中文的预训练模型需要对每个都进行人工标注,这就又陷入了“有多人工就有多少智能”的死胡同。
那么,呱呱落地的BERT为什么能解决这一问题呢?它的优势主要体现在三个方面:
1. BERT拥有一个深而窄的神经网络。transformer的中间层有2018,BERT只有1024,但却有12层。因此,它可以在无需大幅架构修改的前提下进行双向训练。由于是无监督学习,因此不需要人工干预和标注,让低成本地训练超大规模语料成为可能。
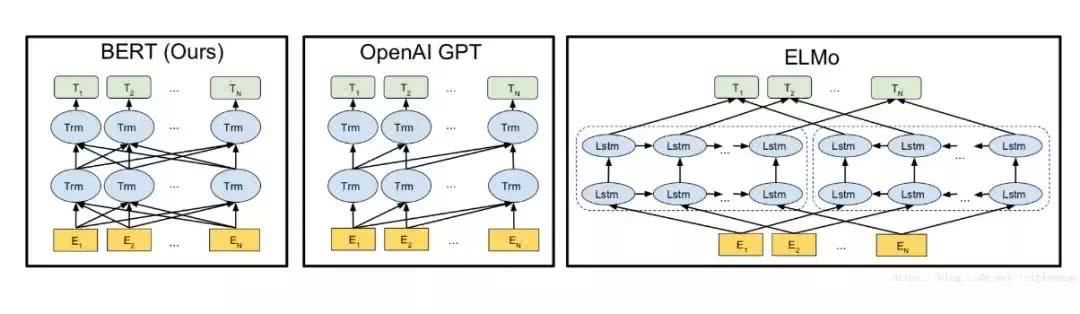
2. BERT模型能够联合神经网络所有层中的上下文来进行训练。这样训练出来的模型在处理问答或语言推理任务时,能够结合上下文理解语义,并且实现更精准的文本预测生成。
3. BERT只需要微调就可以适应很多类型的NLP任务,这使其应用场景扩大,并且降低了企业的训练成本。BERT支持包括中文在内的60种语言,研究人员也不需要从头开始训练自己的模型,只需要利用BERT针对特定任务进行修改,在单个云TPU上运行几小时甚至几十分钟,就能获得不错的分数。
用一些开发者的话来说,就是BERT的“效果好到不敢相信”,这也是其快速蹿红的核心原因。
BERT是如何工作的?
这样厉害的模型,是怎样被训练出来的呢?主要分为五个步骤:
首先,将语料中的某一部分词汇遮盖住,让模型根据上下文双向预测被遮盖的词,来初步训练出通用模型。
然后,从语料中挑选出连续的上下文语句,让transformer模型来识别这些语句是否连续。
这两步合在一起完成预训练,就成为一个能够实现上下文全向预测出的语言表征模型。
最后,再结合精加工(fine tuning)模型,使之适用于具体应用。

而BERT应用起来也非常简单,具体到什么程度呢?个人开发者可以在任意文本语料库上完成“预测下一句”之类的任务。
只需要进行数据生成,把整个输入文件的纯文本做成脚本保存到内存,就可以用BERT进行预训练了。
通过一段简单代码,预训练20步左右,就能得到一个基础的NLP任务模型。如果想在实际应用中有更好的表现,训练10000步以上也不会花费很长时间。
从上述实验成果来看,似乎可以直接得出结论:BERT开启了一个NLP的新世界!
以前我们总是吐槽机器翻译、自然语言理解等NLP技术都是“实验室的人工智能,生活中的“人工智障”,而且每个厂商的语音产品似乎都停留在用论文和跑分隔空叫板,实际应用场景上体验感其实差异并不明显。但BERT的出现,不仅让机器语言理解上有了更好的效果,尤其是上下文理解和文本生成上,表现十分惊艳。更重要的是,它为自然语言处理技术带来的新想象空间。
封神之前,BERT还要面对哪些问题?
说到这里,是不是已经有种“有条件要上BERT,没有条件创造条件也要上BERT”的感觉了?
别急,BERT模型看起来很美好,但并不是一枚谁拿来都能快速见效的“救心丸”,至少有三点需要额外注意:
一是开销巨大,在GPU上跑一次成本很高,而Google推荐的云TPU价格虽然低廉(500美元),却需要两周时间。
二是数据规模要求高。如果没有足够庞大的训练语料,很难在针对性开发中复现同样的评测效果。
三是BERT无法单独完成计算问题,需要后续任务补全推理和决策环节。而且BERT本身是无监督学习,因此不能直接用于解决NLP问题,往往需要结合现有的有监督学习以避免算法歧视或偏见。
目前看来,BERT的魅力虽然让开发者和企业们难以抗拒,但也存在着诸多门槛,想要见效并不是一朝一夕的事儿。但它能够被人吹爆,并不仅仅只是因为算法和数据上的突破,真正的价值还是隐藏在对产业端的推动力量。
BERT带来的想象空间
众所周知,自然语言处理技术被称为AI领域的明珠,但在产业端,智能语音企业对于自家技术的竞争力,不是宣传又在SQuAD这样的顶级赛事中跑了多少分,就是基于各自的数据集大吹特吹准确率。但是,彼此之间的数据往往都十分焦灼,很难真正拉开差距。
而BERT的出现,显然为智能语音技术公司的竞争带来了全新的关键要素,那就是效率,以及成本。
BERT的横空出世,抹平了训练语料的人工标注成本,让超大规模的模型训练不再遥不可及,从而使得产业端研发出交互更友好、理解力更高的语音交互产品成为了可能。
另一方面,在垂直应用端,多种语言支持和低成本地针对性训练,让BERT可以很快在垂直领域进行部署,大大提升了智能语音的配置效率和应用范围,为NLP的产业端实锤落地提供了长期发展的支撑力量。
解决了模型和应用的问题,NLP领域的新赛道自然就落在了语料和算力上。
想要借助BERT训练出更精准、更好的应用模型,考验着企业的两方面能力:一个是训练语料的规模;一个是强大算力的支撑。
BERT使用了超大的数据集(BooksCorpus 800M + English Wikipedia 2.5G单词)和超大的算力(对应于超大模型)来在相关的任务上做预训练。未来,是否有足够的训练语料来复现同样的效果,又是否足够的GPU(背后就是钱)来支撑跑BERT,将是智能语音技术企业拉开身位的关键。

总而言之,BERT在NLP界还是个新生事物,但已经有了封神的潜质。比此前的解决方案更优秀,更有发展潜力。
不过,对数据规模和算力的要求,以及与自身业务的耦合,也在无形中提升着智能语音的门槛和成本。
从这个角度看,最终能够借助BERT拉开竞争区位的,要么是搜狗、阿里、百度这样以搜索、电商为主业的大数据“富一代”,要么是凭借强大效率与业务创新实现“弯道超车”的新独角兽,接下来恐怕可以激发不少新脑洞和解题思路。
无论如何,BERT的出现,终于让专注“跑分”和“隔空叫板”的NLP领域,多了一些更有趣的想象力。
★ 本文系网络转载,转载目的在于传递更多信息,并不代表本网赞同其观点和对其真实性负责。如涉及作品内容、版权和其它问题,请在30日内与本网联系,我们将在第一时间删除内容!
推荐内容 Recommended
- 开启NLP新时代的BE..12-13
- Gartner发布:2..12-12
- 推进高新园区科技创新 ..12-11
- 校企合作的意义与前景展望12-10
相关内容 Related
- 开启NLP新时代的BE..12-13
- Gartner发布:2..12-12
- 推进高新园区科技创新 ..12-11
- 校企合作的意义与前景展望12-10